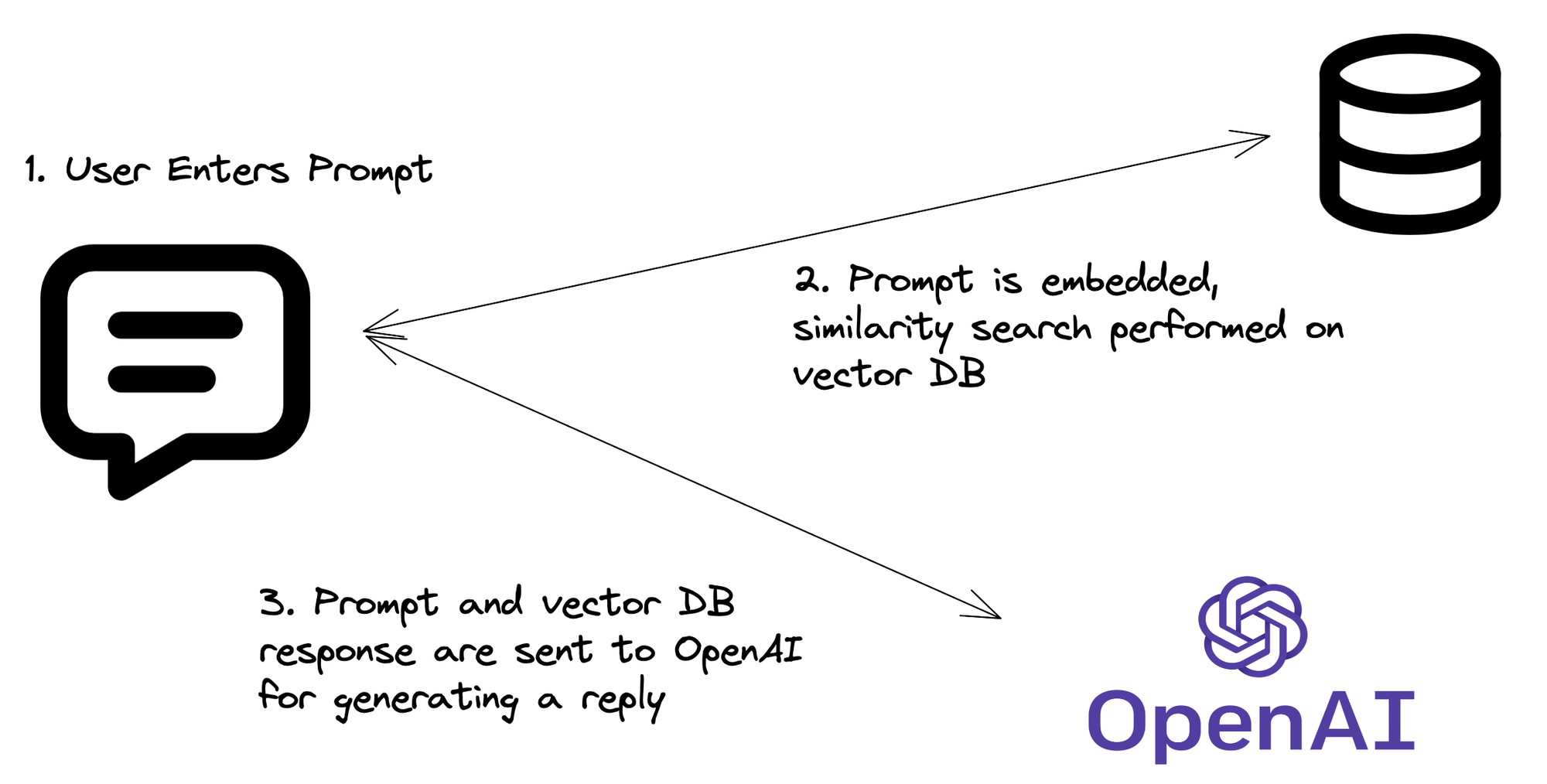
Wir werden ein Backend entwickeln, das die Leistungsfähigkeit von Large Language Models (LLMs) mit der Präzision von Vektordatenbanken unter Verwendung von LangChain kombiniert. Das Ergebnis? Eine API, die Kontext versteht, relevante Informationen abruft und in Echtzeit menschenähnliche Antworten generiert. Es ist nicht nur intelligent; es ist erschreckend intelligent.
Die RAG-Revolution: Warum sollte es dich interessieren?
Bevor wir uns die Ärmel hochkrempeln und mit dem Programmieren beginnen, lassen Sie uns klären, warum RAG in der KI-Welt so viel Aufsehen erregt:
- Kontext ist König: RAG-Systeme verstehen und nutzen den Kontext besser als herkömmliche, auf Schlüsselwörtern basierende Suchen.
- Frisch und relevant: Im Gegensatz zu statischen LLMs kann RAG auf aktuelle Informationen zugreifen und diese nutzen.
- Reduzierung von Halluzinationen: Durch die Verankerung von Antworten in abgerufenen Daten hilft RAG, lästige KI-Halluzinationen zu reduzieren.
- Skalierbarkeit: Wenn Ihre Daten wachsen, wächst auch das Wissen Ihrer KI, ohne dass ständiges Neutraining erforderlich ist.
Der Tech-Stack: Unsere Waffen der Wahl
Wir ziehen nicht unbewaffnet in den Kampf. Hier ist unser Arsenal:
- LangChain: Unser Schweizer Taschenmesser für LLM-Operationen
- Vektordatenbank: Wir verwenden Pinecone, aber Sie können gerne Ihre bevorzugte Datenbank verwenden
- LLM: OpenAI's GPT-3.5 oder GPT-4 (oder ein anderes LLM Ihrer Wahl)
- FastAPI: Zum Erstellen unserer blitzschnellen API-Endpunkte
- Python: Weil, naja, es ist Python
Einrichtung des Spielplatzes
Zuallererst, lassen Sie uns unsere Umgebung vorbereiten. Starten Sie Ihr Terminal und installieren Sie die notwendigen Pakete:
pip install langchain pinecone-client openai fastapi uvicorn
Jetzt erstellen wir eine grundlegende FastAPI-App-Struktur:
from fastapi import FastAPI
from langchain import OpenAI, VectorDBQA
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.vectorstores import Pinecone
import pinecone
import os
app = FastAPI()
# Pinecone initialisieren
pinecone.init(api_key=os.getenv("PINECONE_API_KEY"), environment=os.getenv("PINECONE_ENV"))
# OpenAI initialisieren
llm = OpenAI(temperature=0.7)
# Embeddings initialisieren
embeddings = OpenAIEmbeddings()
# Pinecone-Vektorspeicher initialisieren
index_name = "your-pinecone-index-name"
vectorstore = Pinecone.from_existing_index(index_name, embeddings)
# QA-Kette initialisieren
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", vectorstore=vectorstore)
@app.get("/")
async def root():
return {"message": "Willkommen bei der RAG-gestützten API!"}
@app.get("/query")
async def query(q: str):
result = qa.run(q)
return {"result": result}
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
Aufschlüsselung: Was passiert hier?
Lassen Sie uns diesen Code analysieren, als wäre es ein Frosch im Biologieunterricht (aber viel spannender):
- Wir richten FastAPI als unser Web-Framework ein.
- LangChains
OpenAI-Klasse ist unser Zugang zum LLM. VectorDBQAist der Zauberstab, der unsere Vektordatenbank mit dem LLM für die Beantwortung von Fragen kombiniert.- Wir verwenden Pinecone als unsere Vektordatenbank, aber Sie könnten dies durch Alternativen wie Weaviate oder Milvus ersetzen.
- Der
/query-Endpunkt ist der Ort, an dem die RAG-Magie passiert. Er nimmt eine Frage, führt sie durch unsere QA-Kette und gibt das Ergebnis zurück.
Die RAG-Pipeline: Wie sie tatsächlich funktioniert
Jetzt, da wir den Code haben, lassen Sie uns den RAG-Prozess aufschlüsseln:
- Abfrage-Embedding: Ihre API erhält eine Frage, die dann in ein Vektorembedding umgewandelt wird.
- Vektorsuche: Dieses Embedding wird verwendet, um im Pinecone-Index nach ähnlichen Vektoren (d. h. relevanten Informationen) zu suchen.
- Kontextabruf: Die relevantesten Dokumente oder Abschnitte werden aus Pinecone abgerufen.
- LLM-Magie: Die ursprüngliche Frage und der abgerufene Kontext werden an das LLM gesendet.
- Antwortgenerierung: Das LLM generiert eine Antwort basierend auf der Frage und dem abgerufenen Kontext.
- API-Rückgabe: Ihre API sendet diese intelligente, kontextbewusste Antwort zurück.
Ihr RAG aufladen: Fortgeschrittene Techniken
Bereit, Ihr RAG-System von "ziemlich cool" zu "wow, das ist erstaunlich" zu bringen? Probieren Sie diese fortgeschrittenen Techniken aus:
1. Hybridsuche
Kombinieren Sie die Vektorsuche mit der traditionellen Schlüsselwortsuche für noch bessere Ergebnisse:
from langchain.retrievers import PineconeHybridSearchRetriever
hybrid_retriever = PineconeHybridSearchRetriever(
embeddings=embeddings,
index=vectorstore.pinecone_index
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=hybrid_retriever)
2. Neu-Ranking
Implementieren Sie einen Neu-Ranking-Schritt, um Ihre abgerufenen Dokumente fein abzustimmen:
from langchain.retrievers import RePhraseQueryRetriever
rephraser = RePhraseQueryRetriever.from_llm(
retriever=vectorstore.as_retriever(),
llm=llm
)
qa = VectorDBQA.from_chain_type(llm=llm, chain_type="stuff", retriever=rephraser)
3. Streaming-Antworten
Für ein interaktiveres Erlebnis streamen Sie Ihre API-Antworten:
from fastapi import FastAPI, Response
from fastapi.responses import StreamingResponse
@app.get("/stream")
async def stream_query(q: str):
async def event_generator():
for token in qa.run(q):
yield f"data: {token}\n\n"
return StreamingResponse(event_generator(), media_type="text/event-stream")
Potenzielle Fallstricke: Vorsicht!
So erstaunlich RAG auch ist, es hat seine Eigenheiten. Hier sind einige Dinge, auf die Sie achten sollten:
- Kontextfenster-Beschränkungen: LLMs haben eine maximale Kontextgröße. Stellen Sie sicher, dass Ihre abgerufenen Dokumente diese nicht überschreiten.
- Relevanz vs. Vielfalt: Das Gleichgewicht zwischen relevanten Ergebnissen und vielfältigen Informationen kann schwierig sein. Experimentieren Sie mit Ihren Abrufparametern.
- Halluzinationen sind nicht verschwunden: Während RAG Halluzinationen reduziert, beseitigt es sie nicht. Implementieren Sie immer Schutzmaßnahmen und Faktenprüfmechanismen.
- API-Kosten: Denken Sie daran, dass jede Abfrage potenziell mehrere API-Aufrufe beinhaltet (Embedding, Vektorsuche, LLM). Behalten Sie die Kosten im Auge!
Zusammenfassung: Warum das wichtig ist
Die Implementierung von RAG in Ihrem Backend geht nicht nur darum, an der Spitze der Technologie zu stehen (obwohl das ein netter Bonus ist). Es geht darum, intelligentere, kontextbewusste Anwendungen zu erstellen, die Benutzeranfragen auf eine Weise verstehen und beantworten können, die bisher unmöglich war.
Indem Sie das umfangreiche Wissen von LLMs mit den spezifischen, aktuellen Informationen in Ihrer Vektordatenbank kombinieren, schaffen Sie ein System, das mehr ist als die Summe seiner Teile. Es ist, als ob Sie Ihrer API eine Superkraft verleihen – die Fähigkeit zu verstehen, zu argumentieren und menschenähnliche Antworten basierend auf Echtzeitdaten zu generieren.
"Die Zukunft ist schon da – sie ist nur ungleich verteilt." - William Gibson
Nun, jetzt sind Sie einer der Glücklichen mit einem Stück dieser Zukunft. Gehen Sie hinaus und bauen Sie erstaunliche Dinge!
Denkanstöße
Während Sie RAG in Ihren Projekten implementieren, sollten Sie diese Fragen in Betracht ziehen:
- Wie können Sie die Privatsphäre und Sicherheit der in Ihrem RAG-System verwendeten Daten gewährleisten?
- Welche ethischen Überlegungen spielen bei der Bereitstellung von KI-gestützten APIs eine Rolle?
- Wie könnten sich RAG-Systeme entwickeln, wenn LLMs und Vektordatenbanken weiter fortschreiten?
Die Antworten auf diese Fragen werden die Zukunft von KI-gestützten Anwendungen gestalten. Und jetzt stehen Sie an der Spitze dieser Revolution. Viel Spaß beim Programmieren!