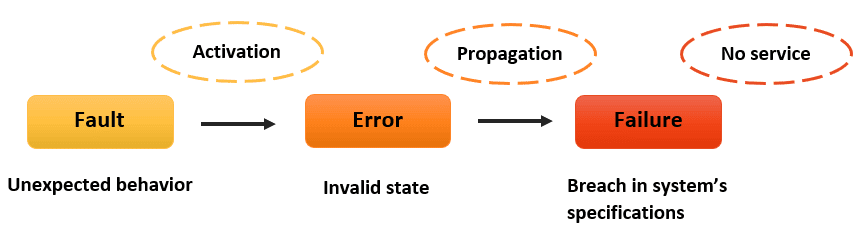
In diesem tiefgehenden Artikel werden wir uns mit fortgeschrittenen Mechanismen zur Fehlerweitergabe beschäftigen. Wir werden untersuchen, wie man eine benutzerdefinierte Fehlertoleranzschicht aufbaut, die selbst die hartnäckigsten Fehler bewältigen kann, und Ihr verteiltes System so robust wie ein Nokia 3310 in einer Welt fragiler Smartphones hält.
Das Problem der Fehlerweitergabe
Bevor wir zur Lösung übergehen, nehmen wir uns einen Moment Zeit, um das Problem zu verstehen. In einem verteilten System sind Fehler wie klatschsüchtige Nachbarn - sie verbreiten sich schnell und können ein ziemliches Chaos verursachen, wenn sie nicht kontrolliert werden.
Betrachten Sie folgendes Szenario:
# Service A
def process_order(order_id):
try:
user = get_user_info(order_id)
items = get_order_items(order_id)
payment = process_payment(user, items)
shipping = arrange_shipping(user, items)
return {"status": "success", "order_id": order_id}
except Exception as e:
return {"status": "error", "message": str(e)}
# Service B
def get_user_info(order_id):
# Simuliert einen Datenbankfehler
raise DatabaseConnectionError("Verbindung zur Benutzerdatenbank nicht möglich")
In diesem einfachen Beispiel wird ein Fehler in Service B zu Service A weitergeleitet und kann potenziell eine Kettenreaktion von Ausfällen verursachen. Aber was wäre, wenn wir diese Fehler abfangen, analysieren und intelligent darauf reagieren könnten? Hier kommt unsere benutzerdefinierte Fehlertoleranzschicht ins Spiel.
Aufbau der Fehlertoleranzschicht
Unsere Fehlertoleranzschicht wird aus mehreren wichtigen Komponenten bestehen:
- Fehlerklassifizierungssystem
- Regelwerk zur Fehlerweitergabe
- Implementierung eines Circuit Breakers
- Wiederholungsmechanismus mit exponentiellem Backoff
- Fallback-Strategien
Schauen wir uns diese Komponenten einzeln an.
1. Fehlerklassifizierungssystem
Der erste Schritt besteht darin, Fehler basierend auf ihrer Schwere und ihrem potenziellen Einfluss zu klassifizieren. Wir erstellen eine benutzerdefinierte Fehlerhierarchie:
class BaseError(Exception):
def __init__(self, message, severity):
self.message = message
self.severity = severity
class TransientError(BaseError):
def __init__(self, message):
super().__init__(message, severity="LOW")
class PartialOutageError(BaseError):
def __init__(self, message):
super().__init__(message, severity="MEDIUM")
class CriticalError(BaseError):
def __init__(self, message):
super().__init__(message, severity="HIGH")
Diese Klassifizierung ermöglicht es uns, Fehler je nach ihrer Schwere unterschiedlich zu behandeln.
2. Regelwerk zur Fehlerweitergabe
Als nächstes erstellen wir ein Regelwerk, um zu entscheiden, wie Fehler in unserem System weitergegeben werden sollen:
class PropagationRulesEngine:
def __init__(self):
self.rules = {
TransientError: self.handle_transient,
PartialOutageError: self.handle_partial_outage,
CriticalError: self.handle_critical
}
def handle_error(self, error):
handler = self.rules.get(type(error), self.default_handler)
return handler(error)
def handle_transient(self, error):
# Implementieren Sie die Wiederholungslogik
pass
def handle_partial_outage(self, error):
# Implementieren Sie die Fallback-Strategie
pass
def handle_critical(self, error):
# Implementieren Sie das Circuit Breaking
pass
def default_handler(self, error):
# Protokollieren und weitergeben
logging.error(f"Nicht behandelter Fehler: {error}")
raise error
Diese Engine ermöglicht es uns, spezifische Verhaltensweisen für verschiedene Fehlertypen zu definieren.
3. Implementierung eines Circuit Breakers
Um Kaskadenausfälle zu verhindern, implementieren wir ein Circuit-Breaker-Muster:
import time
class CircuitBreaker:
def __init__(self, failure_threshold, reset_timeout):
self.failure_count = 0
self.failure_threshold = failure_threshold
self.reset_timeout = reset_timeout
self.last_failure_time = None
self.state = "CLOSED"
def execute(self, func, *args, **kwargs):
if self.state == "OPEN":
if time.time() - self.last_failure_time > self.reset_timeout:
self.state = "HALF-OPEN"
else:
raise CircuitBreakerOpenError("Circuit ist offen")
try:
result = func(*args, **kwargs)
if self.state == "HALF-OPEN":
self.state = "CLOSED"
self.failure_count = 0
return result
except Exception as e:
self.failure_count += 1
if self.failure_count >= self.failure_threshold:
self.state = "OPEN"
self.last_failure_time = time.time()
raise e
Dieser Circuit Breaker wird automatisch "auslösen", wenn eine bestimmte Anzahl von Fehlern auftritt, und verhindert so weitere Aufrufe des problematischen Dienstes.
4. Wiederholungsmechanismus mit exponentiellem Backoff
Für vorübergehende Fehler kann ein Wiederholungsmechanismus mit exponentiellem Backoff äußerst nützlich sein:
import random
import time
def retry_with_backoff(retries=3, backoff_in_seconds=1):
def decorator(func):
def wrapper(*args, **kwargs):
x = 0
while True:
try:
return func(*args, **kwargs)
except TransientError as e:
if x == retries:
raise e
sleep = (backoff_in_seconds * 2 ** x +
random.uniform(0, 1))
time.sleep(sleep)
x += 1
return wrapper
return decorator
@retry_with_backoff(retries=5, backoff_in_seconds=1)
def unreliable_function():
# Simuliert eine unzuverlässige Funktion
if random.random() < 0.7:
raise TransientError("Vorübergehender Fehler")
return "Erfolg!"
Dieser Dekorator wird die Funktion automatisch mit zunehmenden Verzögerungen zwischen den Versuchen wiederholen.
5. Fallback-Strategien
Schließlich implementieren wir einige Fallback-Strategien für den Fall, dass alles andere fehlschlägt:
class FallbackStrategy:
def __init__(self):
self.strategies = {
"get_user_info": self.fallback_user_info,
"process_payment": self.fallback_payment,
"arrange_shipping": self.fallback_shipping
}
def execute_fallback(self, function_name, *args, **kwargs):
fallback = self.strategies.get(function_name)
if fallback:
return fallback(*args, **kwargs)
raise NoFallbackError(f"Keine Fallback-Strategie für {function_name}")
def fallback_user_info(self, order_id):
# Gibt zwischengespeicherte oder Standard-Benutzerinformationen zurück
return {"user_id": "default", "name": "John Doe"}
def fallback_payment(self, user, items):
# Markiert die Zahlung als ausstehend und fährt fort
return {"status": "pending", "message": "Zahlung wird später verarbeitet"}
def fallback_shipping(self, user, items):
# Verwendet eine Standardversandmethode
return {"method": "standard", "estimated_delivery": "5-7 Werktage"}
Diese Fallback-Strategien bieten ein Sicherheitsnetz, wenn normale Abläufe fehlschlagen.
Alles zusammenfügen
Jetzt, da wir alle Komponenten haben, sehen wir uns an, wie sie in unserem verteilten System zusammenarbeiten:
class FaultToleranceLayer:
def __init__(self):
self.rules_engine = PropagationRulesEngine()
self.circuit_breaker = CircuitBreaker(failure_threshold=5, reset_timeout=60)
self.fallback_strategy = FallbackStrategy()
def execute(self, func, *args, **kwargs):
try:
return self.circuit_breaker.execute(func, *args, **kwargs)
except Exception as e:
try:
return self.rules_engine.handle_error(e)
except Exception:
return self.fallback_strategy.execute_fallback(func.__name__, *args, **kwargs)
# Verwendung der Fehlertoleranzschicht
fault_tolerance = FaultToleranceLayer()
@retry_with_backoff(retries=3, backoff_in_seconds=1)
def get_user_info(order_id):
# Tatsächliche Implementierung hier
pass
def process_order(order_id):
user = fault_tolerance.execute(get_user_info, order_id)
# Rest der Bestellverarbeitungslogik
pass
Mit diesem Setup kann unser System eine Vielzahl von Fehlerszenarien elegant bewältigen, Kaskadenausfälle verhindern und die Gesamtzuverlässigkeit verbessern.
Der Gewinn: Ein widerstandsfähigeres System
Durch die Implementierung dieser benutzerdefinierten Fehlertoleranzschicht haben wir die Widerstandsfähigkeit unseres verteilten Systems erheblich verbessert. Hier ist, was wir gewonnen haben:
- Intelligente Fehlerbehandlung basierend auf Fehlertyp und Schweregrad
- Automatische Wiederholungen bei vorübergehenden Ausfällen
- Schutz vor Kaskadenausfällen mit Circuit Breakern
- Sanfte Degradierung durch Fallback-Strategien
- Verbesserte Sichtbarkeit von Fehlermustern und Systemverhalten
Denken Sie daran, dass der Aufbau eines fehlertoleranten verteilten Systems ein fortlaufender Prozess ist. Überwachen Sie kontinuierlich das Verhalten Ihres Systems, verfeinern Sie Ihre Fehlerbehandlungsstrategien und passen Sie sich an neue Ausfallmodi an, sobald sie auftreten.
Denkanstöße
Wenn Sie Ihre eigene Fehlertoleranzschicht implementieren, sollten Sie folgende Fragen berücksichtigen:
- Wie werden Sie mit Fehlern umgehen, die nicht genau in Ihr Klassifizierungssystem passen?
- Welche Metriken werden Sie verwenden, um die Effektivität Ihrer Fehlertoleranzmechanismen zu bewerten?
- Wie werden Sie den Wunsch nach Widerstandsfähigkeit mit der Notwendigkeit der Systemreaktionsfähigkeit in Einklang bringen?
- Wie können Sie diese Fehlertoleranzschicht nutzen, um die Beobachtbarkeit Ihres Systems zu verbessern?
Denken Sie daran, dass Fehler in der Welt der verteilten Systeme nicht nur unvermeidlich sind - sie sind eine Gelegenheit, Ihr System stärker zu machen. Viel Erfolg bei der Fehlerbehandlung!