Warum Hazelcast? Und warum sollte es Sie interessieren?
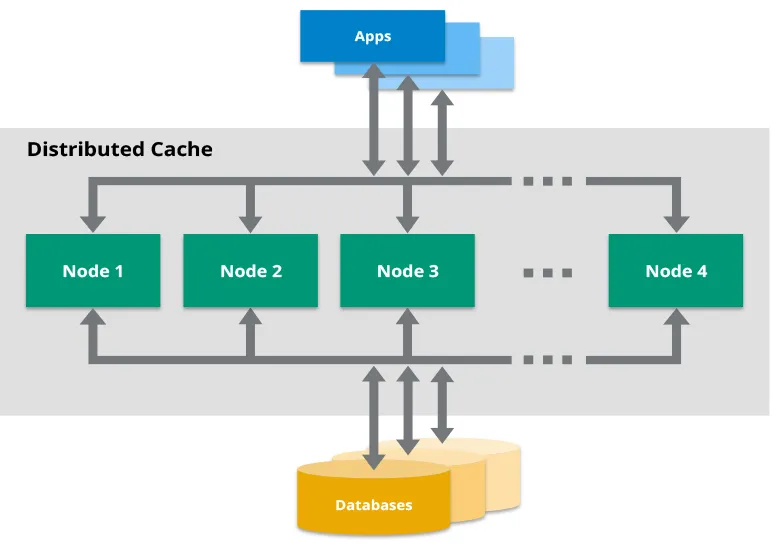
Bevor wir ins Detail gehen, stellen wir uns die Frage: Warum Hazelcast? In der großen Welt der Caching-Lösungen hebt sich Hazelcast als verteiltes In-Memory-Datenraster hervor, das hervorragend mit Java harmoniert. Es ist wie Redis, aber mit einem Java-zentrierten Ansatz und einigen cleveren Funktionen, die verteiltes Caching in Microservices zum Kinderspiel machen.
Hier sind einige Gründe, warum Hazelcast Ihr neuer bester Freund werden könnte:
- Native Java-API (kein Kampf mehr mit der Serialisierung)
- Verteilte Berechnungen (denken Sie an MapReduce, aber einfacher)
- Eingebauter Split-Brain-Schutz (weil Netzwerkpartitionen passieren)
- Einfache Skalierung (einfach mehr Knoten hinzufügen)
Einrichtung von Hazelcast in Ihren Microservices
Fangen wir mit den Grundlagen an. Hazelcast zu Ihrem Java-Microservice hinzuzufügen, ist überraschend einfach. Fügen Sie zuerst die Abhängigkeit zu Ihrer pom.xml hinzu:
<dependency>
<groupId>com.hazelcast</groupId>
<artifactId>hazelcast</artifactId>
<version>5.1.1</version>
</dependency>
Nun erstellen wir eine einfache Hazelcast-Instanz:
import com.hazelcast.core.Hazelcast;
import com.hazelcast.core.HazelcastInstance;
public class CacheConfig {
public HazelcastInstance hazelcastInstance() {
return Hazelcast.newHazelcastInstance();
}
}
Voilà! Sie haben jetzt einen Hazelcast-Knoten, der in Ihrem Microservice läuft. Aber das ist noch nicht alles!
Erweiterte Caching-Muster
Nachdem wir die Grundlagen abgedeckt haben, schauen wir uns einige erweiterte Caching-Muster an, die Ihre Microservices zum Singen bringen werden.
1. Read-Through/Write-Through Caching
Dieses Muster ist wie ein persönlicher Assistent für Ihre Daten. Anstatt manuell zu verwalten, was in den Cache geht und was herauskommt, kann Hazelcast das für Sie übernehmen.
public class UserCacheStore implements MapStore<String, User> {
@Override
public User load(String key) {
// Aus der Datenbank laden
}
@Override
public void store(String key, User value) {
// In der Datenbank speichern
}
// Weitere Methoden...
}
MapConfig mapConfig = new MapConfig("users");
mapConfig.setMapStoreConfig(new MapStoreConfig().setImplementation(new UserCacheStore()));
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Mit dieser Konfiguration lädt Hazelcast automatisch Daten aus Ihrer Datenbank, wenn sie nicht im Cache sind, und schreibt Daten zurück in die Datenbank, wenn sie im Cache aktualisiert werden. Es ist wie Magie, aber besser, weil es einfach gute Ingenieurskunst ist.
2. Near Cache Pattern
Manchmal müssen Daten blitzschnell sein, selbst in einer verteilten Umgebung. Hier kommt das Near Cache Pattern ins Spiel. Es ist wie ein Cache für Ihren Cache. Meta, oder?
NearCacheConfig nearCacheConfig = new NearCacheConfig();
nearCacheConfig.setName("users");
nearCacheConfig.setTimeToLiveSeconds(300);
MapConfig mapConfig = new MapConfig("users");
mapConfig.setNearCacheConfig(nearCacheConfig);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Diese Konfiguration erstellt einen lokalen Cache auf jedem Hazelcast-Knoten, reduziert Netzwerkanfragen und beschleunigt Leseoperationen. Es ist besonders nützlich für Daten, die häufig gelesen, aber selten aktualisiert werden.
3. Eviction Policies
Speicher ist kostbar, besonders in Microservices. Hazelcast bietet ausgeklügelte Eviction-Policies, um sicherzustellen, dass Ihr Cache nicht zum Speicherfresser wird.
MapConfig mapConfig = new MapConfig("users");
mapConfig.setEvictionConfig(
new EvictionConfig()
.setEvictionPolicy(EvictionPolicy.LRU)
.setMaxSizePolicy(MaxSizePolicy.PER_NODE)
.setSize(10000)
);
Config config = new Config();
config.addMapConfig(mapConfig);
HazelcastInstance hz = Hazelcast.newHazelcastInstance(config);
Diese Konfiguration richtet eine LRU (Least Recently Used) Eviction-Policy ein, die sicherstellt, dass Ihr Cache innerhalb eines Limits von 10.000 Einträgen pro Knoten bleibt. Es ist wie ein Türsteher für Ihre Datenparty, der die am wenigsten beliebten Einträge rauswirft, wenn es zu voll wird.
Verteilte Berechnungen: Auf die nächste Stufe heben
Caching ist großartig, aber Hazelcast kann mehr. Schauen wir uns an, wie wir verteilte Berechnungen nutzen können, um unsere Microservices zu beschleunigen.
1. Distributed Executor Service
Müssen Sie eine Aufgabe über Ihren gesamten Cluster ausführen? Der Distributed Executor Service von Hazelcast hilft Ihnen dabei.
public class UserAnalytics implements Callable<Map<String, Integer>>, HazelcastInstanceAware {
private transient HazelcastInstance hazelcastInstance;
@Override
public Map<String, Integer> call() {
IMap<String, User> users = hazelcastInstance.getMap("users");
// Analysen auf lokalen Daten durchführen
return results;
}
@Override
public void setHazelcastInstance(HazelcastInstance hazelcastInstance) {
this.hazelcastInstance = hazelcastInstance;
}
}
HazelcastInstance hz = Hazelcast.newHazelcastInstance();
IExecutorService executorService = hz.getExecutorService("analytics-executor");
Set<Member> members = hz.getCluster().getMembers();
Map<Member, Future<Map<String, Integer>>> results = executorService.submitToMembers(new UserAnalytics(), members);
// Ergebnisse zusammenführen
Map<String, Integer> finalResults = new HashMap<>();
for (Future<Map<String, Integer>> future : results.values()) {
Map<String, Integer> result = future.get();
// Ergebnis in finalResults zusammenführen
}
Dieses Muster ermöglicht es Ihnen, Berechnungen auf Daten dort durchzuführen, wo sie sich befinden, was die Datenbewegung reduziert und die Leistung verbessert. Es ist, als würde man die Funktion zu den Daten bringen, anstatt umgekehrt.
2. Entry Processors
Müssen Sie mehrere Einträge in Ihrem Cache atomar aktualisieren? Entry Processors sind Ihre Freunde.
public class UserUpgradeEntryProcessor implements EntryProcessor<String, User, Object> {
@Override
public Object process(Map.Entry<String, User> entry) {
User user = entry.getValue();
if (user.getPoints() > 1000) {
user.setStatus("GOLD");
entry.setValue(user);
}
return null;
}
}
IMap<String, User> users = hz.getMap("users");
users.executeOnEntries(new UserUpgradeEntryProcessor());
Dieses Muster ermöglicht es Ihnen, Operationen auf mehreren Einträgen durchzuführen, ohne dass explizite Sperrungen oder Transaktionsmanagement erforderlich sind. Es ist wie eine Mini-Transaktion für jeden Eintrag in Ihrem Cache.
Fallstricke, auf die Sie achten sollten
Wie bei jedem leistungsstarken Werkzeug gibt es auch bei Hazelcast einige potenzielle Fallstricke. Hier sind einige, die Sie beachten sollten:
- Übermäßiges Caching: Nicht alles muss zwischengespeichert werden. Seien Sie wählerisch, was Sie in Hazelcast speichern.
- Ignorieren der Serialisierung: Hazelcast muss Objekte serialisieren. Stellen Sie sicher, dass Ihre Objekte serialisierbar sind, und ziehen Sie benutzerdefinierte Serializer für komplexe Objekte in Betracht.
- Vernachlässigung der Überwachung: Richten Sie eine ordnungsgemäße Überwachung für Ihren Hazelcast-Cluster ein. Tools wie das Hazelcast Management Center können von unschätzbarem Wert sein.
- Vergessen der Konsistenz: In einem verteilten System ist die eventual consistency oft die Norm. Entwerfen Sie Ihre Anwendung entsprechend.
Zusammenfassung
Wir haben viel abgedeckt, von der grundlegenden Einrichtung bis hin zu erweiterten Caching-Mustern und verteilten Berechnungen. Hazelcast ist ein leistungsstarkes Werkzeug, das die Leistung und Skalierbarkeit Ihrer Java-Microservices erheblich steigern kann. Aber denken Sie daran, mit großer Macht kommt große Verantwortung. Nutzen Sie diese Muster weise und berücksichtigen Sie immer die spezifischen Bedürfnisse Ihrer Anwendung.
Nun, gehen Sie und cachen Sie wie ein Profi! Ihre Microservices (und Ihre Benutzer) werden es Ihnen danken.
"Der schnellste Datenzugriff ist der, den Sie überhaupt nicht durchführen müssen." - Unbekannter Caching-Guru (wahrscheinlich)
Weiterführende Lektüre
Wenn Sie mehr wissen möchten, schauen Sie sich diese Ressourcen an:
Viel Spaß beim Cachen!